

[ad_1]
Meta has released the most up to date entrance in its Llama collection of open resource generative AI versions: Llama 3. Or, extra properly, the firm has open sourced 2 versions in its brand-new Llama 3 family members, with the remainder to find at an undefined future day.
Meta defines the brand-new versions– Llama 3 8B, which consists of 8 billion criteria, and Llama 3 70B, which consists of 70 billion criteria– as a “significant jump” contrasted to the previous-gen Llama versions, Llama 2 8B and Llama 2 70B, performance-wise. (Specifications basically specify the ability of an AI design on an issue, like evaluating and creating message; higher-parameter-count versions are, usually talking, extra qualified than lower-parameter-count versions.) Actually, Meta states that, for their corresponding criterion matters, Llama 3 8B and Llama 3 70B– trained on 2 customized 24,000 GPU collections– are are amongst the best-performing generative AI versions offered today.
That’s rather a case to make. So exactly how is Meta sustaining it? Well, the firm indicates the Llama 3 versions’ ratings on preferred AI standards like MMLU (which tries to gauge expertise), ARC (which tries to gauge ability procurement) and decrease (which checks a design’s thinking over pieces of message). As we’ve written about before, the effectiveness– and credibility– of these standards is up for argument. But also for far better or even worse, they continue to be among minority standard methods through which AI gamers like Meta review their versions.
Llama 3 8B bests various other open resource versions like Mistral’s Mistral 7B and Google’s Gemma 7B, both of which consist of 7 billion criteria, on at the very least 9 standards: MMLU, ARC, DECREASE, GPQA (a collection of biology-, physics- and chemistry-related inquiries), HumanEval (a code generation examination), GSM-8K (mathematics word issues), MATHEMATICS (an additional math criteria), AGIEval (an analytical examination collection) and BIG-Bench Hard (a realistic thinking assessment).
Currently, Mistral 7B and Gemma 7B aren’t precisely on the bleeding side (Mistral 7B was launched last September), and in a few of standards Meta mentions, Llama 3 8B ratings just a few percent factors more than either. However Meta additionally makes the case that the larger-parameter-count Llama 3 design, Llama 3 70B, is affordable with front runner generative AI versions consisting of Gemini 1.5 Pro, the most up to date in Google’s Gemini collection.
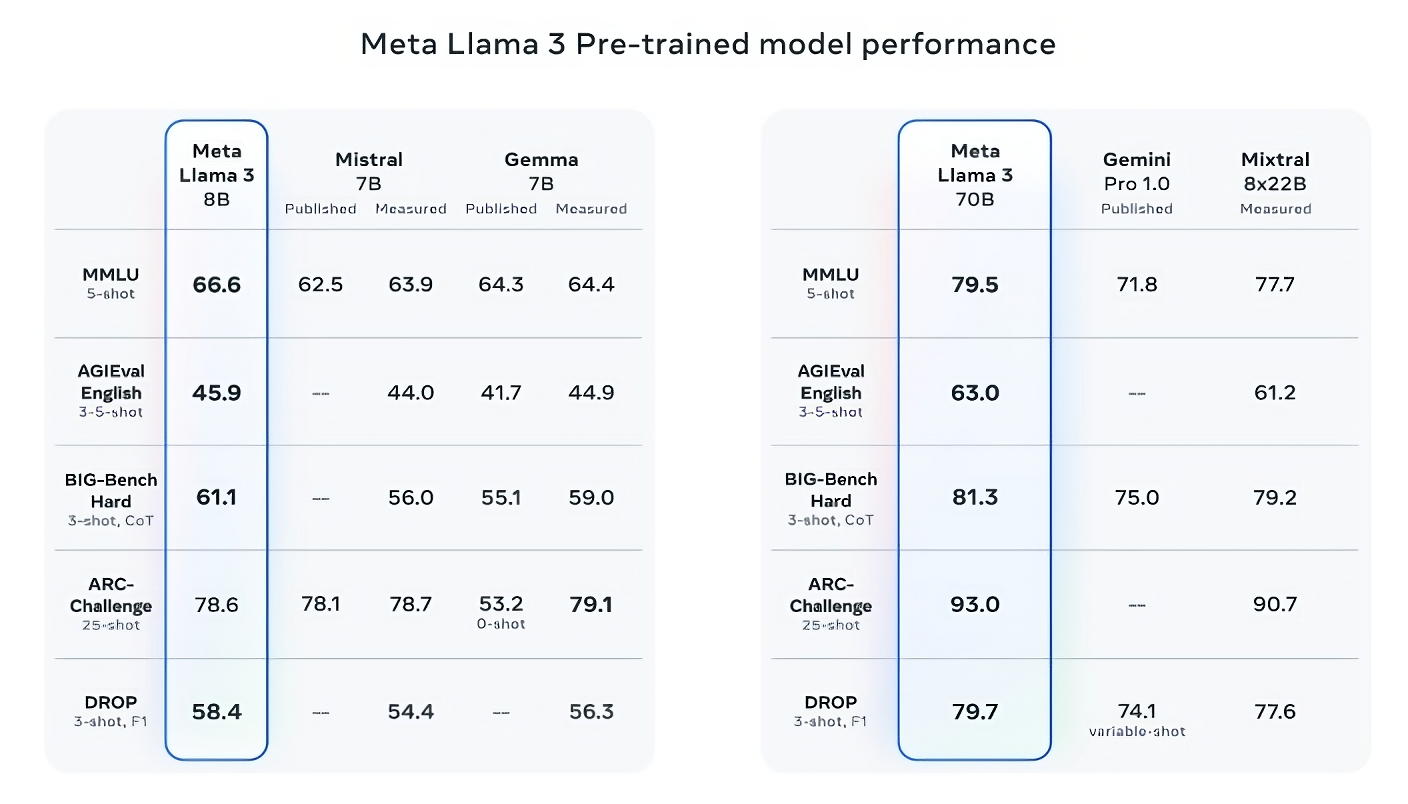
Picture Credit scores: Meta
Llama 3 70B defeats Gemini 1.5 Pro on MMLU, HumanEval and GSM-8K, and– while it does not competing Anthropic’s the majority of performant design, Claude 3 Piece– Llama 3 70B ratings far better than the weakest design in the Claude 3 collection, Claude 3 Sonnet, on 5 standards (MMLU, GPQA, HumanEval, GSM-8K and Mathematics).
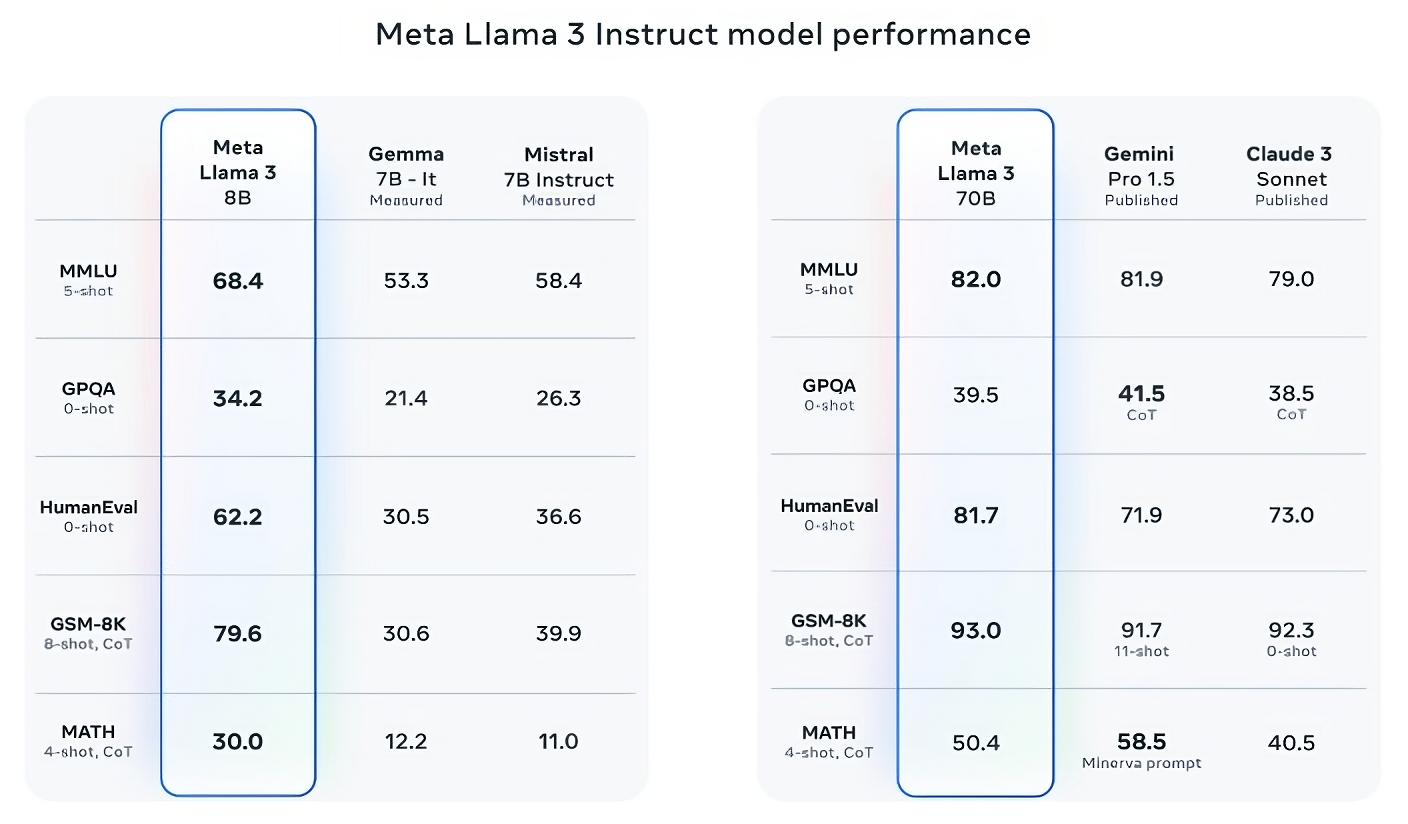
Picture Credit Reports: Meta
For what it deserves, Meta additionally established its very own examination established covering usage instances varying from coding and producing contacting thinking to summarization, and– shock!– Llama 3 70B triumphed versus Mistral’s Mistral Tool design, OpenAI’s GPT-3.5 and Claude Sonnet. Meta states that it gated its modeling groups from accessing the readied to keep neutrality, yet certainly– considered that Meta itself created the examination– the outcomes need to be taken with a grain of salt.

Picture Credit scores: Meta
More qualitatively, Meta states that individuals of the brand-new Llama versions must anticipate extra “steerability,” a reduced chance to reject to address inquiries and greater precision on facts inquiries, inquiries concerning background and STEM areas such as design and scientific research and basic coding suggestions. That remains in component many thanks to a much bigger information collection: a collection of 15 trillion symbols, or an overwhelming ~ 750,000,000,000 words– 7 times the dimension of the Llama 2 training collection. (In the AI area, “symbols” describes partitioned littles raw information, like the syllables “follower,” “tas” and “tic” in words “great.”)
Where did this information originate from? Excellent concern. Meta would not claim, exposing just that it attracted from “openly offered resources,” consisted of 4 time extra code than in the Llama 2 training information established which a section of the collection– 5%– has non-English information (in ~ 30 languages) to enhance efficiency on languages apart from English. Meta additionally claimed it utilized artificial information– i.e. AI-generated information– to develop longer records for the Llama 3 versions to educate on, a somewhat controversial approach as a result of the prospective efficiency downsides.
” While the versions we’re launching today are just tweaked for English outcomes, the boosted information variety assists the versions much better acknowledge subtleties and patterns, and carry out highly throughout a selection of jobs,” Meta creates in a post shown to TechCrunch.
Numerous generative AI suppliers see training information as an affordable benefit and hence maintain it and details concerning it near the upper body. However training information information are additionally a possible resource of IP-related claims, an additional disincentive to expose a lot. Recent reporting disclosed that Meta, in its pursuit to keep rate with AI competitors, at one factor utilized copyrighted digital books for AI training in spite of the firm’s very own attorneys’ cautions; Meta and OpenAI are the topic of a continuous suit brought by writers consisting of comic Sarah Silverman over the suppliers’ claimed unapproved use copyrighted information for training.
So what regarding poisoning and prejudice, 2 various other usual issues with generative AI versions (including Llama 2)? Does Llama 3 enhance in those locations? Yes, asserts Meta.
Meta states that it established brand-new data-filtering pipes to improve the high quality of its design training information, which it’s upgraded its set of generative AI security collections, Llama Guard and CybersecEval, to try to avoid the abuse of and undesirable message generations from Llama 3 versions and others. The firm’s additionally launching a brand-new device, Code Guard, developed to discover code from generative AI versions that could present protection susceptabilities.
Filtering isn’t fail-safe, however– and devices like Llama Guard, CybersecEval and Code Guard just presume. (See: Llama 2’s propensity to make up answers to questions and leak private health and financial information.) We’ll need to wait and see exactly how the Llama 3 versions carry out in the wild, comprehensive of screening from academics on different standards.
Meta states that the Llama 3 versions– which are offered for download currently, and powering Meta’s Meta AI aide on Facebook, Instagram, WhatsApp, Carrier and the internet– will certainly quickly be organized in handled kind throughout a variety of cloud systems consisting of AWS, Databricks, Google Cloud, Hugging Face, Kaggle, IBM’s WatsonX, Microsoft Azure, Nvidia’s NIM and Snow. In the future, variations of the versions enhanced for equipment from AMD, AWS, Dell, Intel, Nvidia and Qualcomm will certainly additionally be provided.
And even more qualified versions are on the perspective.
Meta states that it’s presently educating Llama 3 versions over 400 billion criteria in dimension– versions with the capacity to “speak in numerous languages,” take even more information in and comprehend pictures and various other methods along with message, which would certainly bring the Llama 3 collection in accordance with open launches like Embracing Face’s Idefics2.

Picture Credit scores: Meta
” Our objective in the future is to make Llama 3 multilingual and multimodal, have longer context and remain to enhance total efficiency throughout core [large language model] capacities such as thinking and coding,” Meta creates in a post. “There’s a great deal even more to find.”
Indeed.
[ad_2]
Source link .

{kind=link}